Siim Tiilen
Due to the ever increasing importance of AI in our stack, we are extensively using graphics processing units (GPUs) in Kubernetes to run various machine learning (ML) workloads. In this blog, I’ll describe how we have been sharing GPUs between pods for the last 2 years to massively reduce our infrastructure cost.
NVIDIA GPU usage example
When using NVIDIA GPU's, you need to use the NVIDIA device plugin for Kubernetes that declares a new custom resource, nvidia.com/gpu , which you can use to assign GPUs to Kubernetes pods. The issue with this approach is that you cannot split them between multiple applications (PODs) and GPU's are a very expensive resource.
```yaml
apiVersion: v1
kind: Pod
metadata:
name: gpu-example
spec:
restartPolicy: OnFailure
containers:
- name: gpu-example
image: eritikass/gpu-load-test
imagePullPolicy: Always
resources:
limits:
nvidia.com/gpu: 1
```So what happens when you deploy a GPU using applications like this? Kubernetes is using the nvidia.com/gpu resource to deploy this pod into a node where a GPU is available.
If you connect (ssh) into the node where this pod is running, and use nvidia-smi command there, you can get a result similar to this.
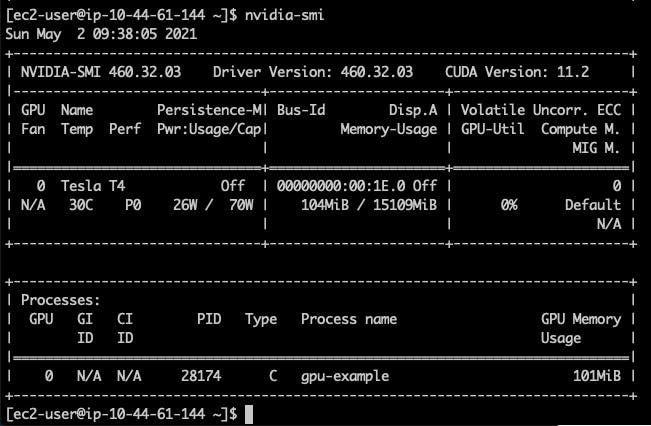
The info visible here is that our node has 1 NVIDIA Tesla T4 GPU with 15109MiB of memory and we are using 104MiB of that with one process (our deployed pod).
Internally there is one very important variable that is given to each pod and the application is using this to know which GPUs to use.

# connect to pod kubectl exec -it pod/gpu-example -- bash #and check echo $NVIDIA_VISIBLE_DEVICES
In the example above, this GPU - GPU-93955ff6-1bbe-3f6d-8d58-a2104edb62db - is being used by the application. When you have a node with multiple GPUs, then actually all pods can access all GPUs - but they all are using this variable to know which GPU they should access.
This variable also has one "magical" value: all. Using this you can override GPU allocation and let your application know that it can use any (all) GPUs present in your node.
Sharing GPU MVP
We know that our example application is using 104MiB and the GPU has a total 15109MiB, so in theory we can fit it 145 times into the same GPU.
In the next example you need to have AWS EKS cluster with 1 GPU instance (g4dn.xlarge), and with some modifications it should be possible to use it in any Kubernetes cluster with Nvidia GPU nodes available.
```yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: gpu-example
spec:
# In this example lets run 5 pods for demo purposes.
#
# NB: aws g4 nodes can run maxium of 29 pods due networking limits,
# https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/using-eni.html#AvailableIpPerENI
replicas: 5
selector:
matchLabels:
app: gpu-example
template:
metadata:
labels:
app: gpu-example
spec:
# Lets use affinity to make sure pod(s) in this deployment
# can be only assigned to nodes that are using g4dn.xlarge instance.
# This way we can be sure there is GPU available.
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: node.kubernetes.io/instance-type
operator: In
values:
- g4dn.xlarge
containers:
- name: gpu-example
image: eritikass/gpu-load-test
env:
# this will let cuda application know to use any GPU available
- name: NVIDIA_VISIBLE_DEVICES
value: all
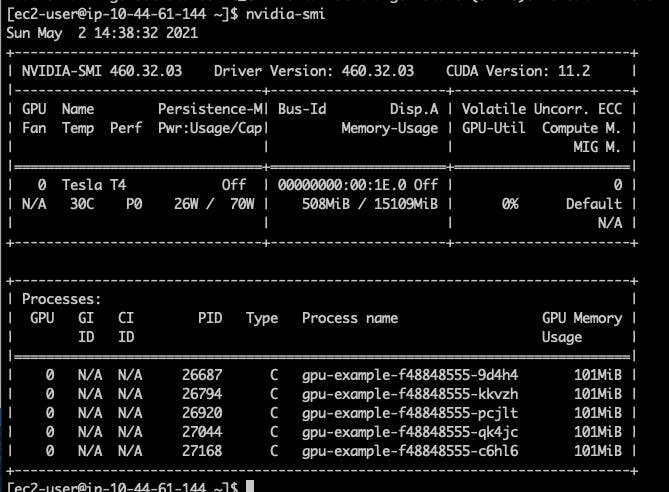
```If we check after that we can see that all 5 pods are assigned to the same node.

And when we check nvidia-smi in this node we can see there are 5 GPU processes running from those pods.
Using custom resources
Now when we know that multiple GPU-using pods can run in the same node, we need to make sure they are split between nodes based on the node's capacity to handle the pod’s requirements. For this we can use Custom Resources to let all GPU nodes know that they have so much GPU memory available to use.
We will be using DaemonSet to add custom GPU memory resource (we named it veriff.com/gpu-memory) to add nodes with an NVIDIA GPU attached. DaemonSet is a special type of Kubernetes deployment that will run 1 pod in some (or all) cluster nodes, it is quite often used to deploy things like log collectors and monitoring tooling. Our DaemonSet will have nodeAffinity to make sure it will only run in g4dn.xlarge nodes.
```yaml
---
#
# config maps that is holding the script that is run inside DaemonSet in all gpu nodes to set gpu memory
#
apiVersion: v1
kind: ConfigMap
metadata:
name: add-gpu-memory
namespace: kube-system
data:
app.sh: |
#!/bin/bash
gpu_memory_value="15079Mi"
timeout 240 kubectl proxy &
sleep 3
curl --header "Content-Type: application/json-patch+json" \
--request PATCH \
--max-time 10 --retry 10 --retry-delay 2 \
--data "[{\"op\": \"add\", \"path\": \"/status/capacity/veriff.com~1gpu-memory\", \"value\": \"${gpu_memory_value}\"}]" \
"http://127.0.0.1:8001/api/v1/nodes/${K8S_NODE_NAME}/status"
echo " * ${gpu_memory_value} of gpu memory added to ${K8S_NODE_NAME} (veriff.com/gpu-memory)"
sleep infinity
---
#
# this DaemonSet will run in all g4dn.xlarge nodes and patching them to add them gpu memory custom resources
#
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: add-gpu-memory
namespace: kube-system
spec:
selector:
matchLabels:
name: add-gpu-memory
template:
metadata:
labels:
name: add-gpu-memory
spec:
tolerations:
- key: "special"
operator: "Exists"
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: node.kubernetes.io/instance-type
operator: In
values:
- g4dn.xlarge
serviceAccountName: add-gpu-memory
containers:
- name: add-gpu-memory
image: bitnami/kubectl
resources:
limits:
cpu: 40m
memory: 50M
requests:
cpu: 1m
memory: 1M
volumeMounts:
- mountPath: /app.sh
name: code
readOnly: true
subPath: app.sh
command:
- bash
- /app.sh
env:
#
# this variable is used in script to patch nodes to know what node he is running
#
- name: "K8S_NODE_NAME"
valueFrom:
fieldRef:
apiVersion: "v1"
fieldPath: "spec.nodeName"
priorityClassName: system-node-critical
volumes:
- name: code
configMap:
name: add-gpu-memory
#
# rbac permissions used by daemonset to patch nodes
#
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: add-gpu-memory
namespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: add-gpu-memory
namespace: kube-system
rules:
- apiGroups:
- "*"
resources:
- nodes
verbs:
- get
- list
- apiGroups:
- "*"
resources:
- nodes/status
verbs:
- patch
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: add-gpu-memory
namespace: kube-system
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: add-gpu-memory
subjects:
- kind: ServiceAccount
name: add-gpu-memory
namespace: kube-system
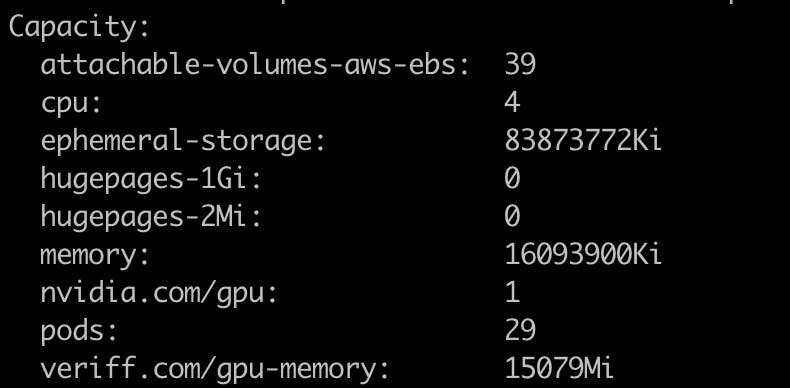
```If you check your node using “kubectl describe node/NAME” you can see it has veriff.com/gpu-memory resource available.
Now when we know that our gpu memory adding script works, let's scale our cluster up so we have multiple GPU nodes available.
In order to test it out, we will modify our deployment to use this new resource.
```yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: gpu-example
spec:
replicas: 6
selector:
matchLabels:
app: gpu-example
template:
metadata:
labels:
app: gpu-example
spec:
containers:
- name: gpu-example
image: eritikass/gpu-load-test
env:
# this will let cuda application know to use any GPU available
- name: NVIDIA_VISIBLE_DEVICES
value: all
resources:
requests:
veriff.com/gpu-memory: 104Mi
limits:
veriff.com/gpu-memory: 104Mi
```After that it is visible that pods are split between nodes.

With regular resources like CPU and memory, kubernetes will know how much pods (containers) are actually using and if anyone tries to use more - kubernetes will restrict it. However with our new custom resource, there is no actual safeguard in place that some “evil” pod can’t take more GPU memory than declared. So you need to be very careful when setting the resources there. When pods try to use more GPU memory than a node has available, it usually results in some very ugly crashes.
In Veriff, we resolved this issue with extensive monitoring and alerting for our new GPU Custom Resources usage. We have also developed tooling in-house to measure ML applications GPU usage under load.
All code examples from this post can be found in https://github.com/Veriff/gpu-sharing-examples.
